5 Key Succes Factors for Data Intelligence

It astonishes me sometimes what people think AI is. It’s like a miracle box: you give your data to a vendor and by some magic suddenly a model comes out that predicts whatever you want to predict or detects any anomaly you could think of… O hell, wait, what a bummer. That’s not how it works.
At sAInce.io we believe in 5 success factors to open up the power of data intelligence. In this blog we’ll go through each one of them and explain why they are important to be successful in ‘big data’ projects.

1 – Vision supported by Upper Management
It’s true that ‘Business Intelligence’ is driven or originated in a lot of organizations by Finance and Sales. But they don’t have the same kind of challenges that manufacturing plants face.
In manufacturing it’s about efficiency, speed-to-market, yield, predictive maintenance, avoiding machine breakdowns and stand-stills etc. And yes, these have an impact on your finance and sales KPIs.
But MES and machine data require new technologies. We can’t put all our time series data in an RDBMS. And we want to leverage our time series data for data science purposes for sure. So we need easy access to those data and be able to query, analyse and transform those data easily.
And we need strategies to deal with these data in the long term. Do we want to keep data points at 5 seconds, 10 seconds etc? Also if the data is older than x years? What are our data retention schedules? What about compliance requirements?
There’s no big data project that can succeed without a vision supported by the upper management. It makes no sense that only small project teams try to leverage data intelligence. And it’s a shame that some organizations don’t merit the efforts of those small teams.
In the end, you’ll need a vision and a roadmap to get to data intelligence. And it’s the management that will need to spread this vision amongst the organization.
2 – The data lake as the Foundation Layer for your data
Building intelligent machines or devices requires data. Machine learning algorithms cannot predict accurately without being trained on a dataset large enough to understand the general characteristics of those data. After all, Machine Learning algorithms need to find the general trends in your data to predict a pattern or an anomaly.
Does this mean you need to invest first years and years in building the perfect data warehouse so you can leverage your data? We don’t think so. Setting up a big pile of data without having a clue on where it will lead you to, doesn’t make much sense. It doesn’t provide you any intelligence. It’s just a big pile of data, nothing more.
On the other hand, is it then better to provide access to all your data sources to data scientists so they can explore the data and build ML models?
Maybe yes, initially for a PoC. But how will you then leverage those ML models? You really need a well-designed data foundation layer to productionize your data intelligence.
So yes, you need to invest in a well designed data layer. But keep mixed priorities. Don’t invest only in the leverage of your ERP and other global systems. Your data architecture really needs to support also manufacturing intelligence. Hence invest also in the leverage of MES and equipment data.
3 – Data Intelligence starts with process knowledge!
Ok, so let’s bring in some data scientists and let the magic happen.
That won’t work. To bring intelligence in your data you need to understand the processes that are involved. We need to understand how a typical process runs, what deviations are expected in which circumstances. How we can ‘read’ some of the typical process steps: is this accurately monitored by a PLC tag or do we need to derive it from a sudden drop in pressure etc.
A big data project can only succeed if the team involves the process engineers and if the process engineers have enough time to work on the project apart from their day to day tasks.
4 – Real Data Intelligence requires data science!
Of course we need data scientists. Data scientists are experts in feature engineering and have a good understanding of the statistics, math and algorithms that are the basis for each ML model.
They can deal with large amounts of data and have knowledge of the applicable programming languages like Python or R. Data scientists have a strong analytical mindset and have to be the bridge between the process engineers and the final data intelligence. So strong communication skills are equally important.
It’s not easy to find all these characteristics in one person. That’s one of the reasons why the job of Data Scientist is sometimes called ‘the sexiest job in the 21st century’.
Without ML models we are actually doing Business Intelligence and get Data Insights. We can visualize a lot and nowadays most BI tools even use some kind of ML model to help you visualize data. That will give us insight, but not real intelligence. Intelligence is about predicting patterns, not merely visualizing actual or historical data.
5 – Integrate with existing or new software systems!
Software engineers have a broad understanding how software systems can be integrated. They know how they can build loosely coupled software modules (a.k.a. Micro Services), how they can be available 24 7/7 etc. These are the people that can ensure that all the investments made in developing a ML model can also be applied on the production floor.
They are experts in software development, micro service architectures, front-end architectures, data streaming services etc. We need them to productionize our intelligent data systems on real-time data.
It’s nice if we analyse our processes based on historical data and are able to prove that our model will work. However, we need to run this on actual real-time data so the model can help us in predicting failures, anomalies etc.
We actually want to take action in real-time and hence improve our processes.
And when we are able to create a closed loop (automatic adjustment of our processes based on the predictions), that’s when AI is born.
Conclusions
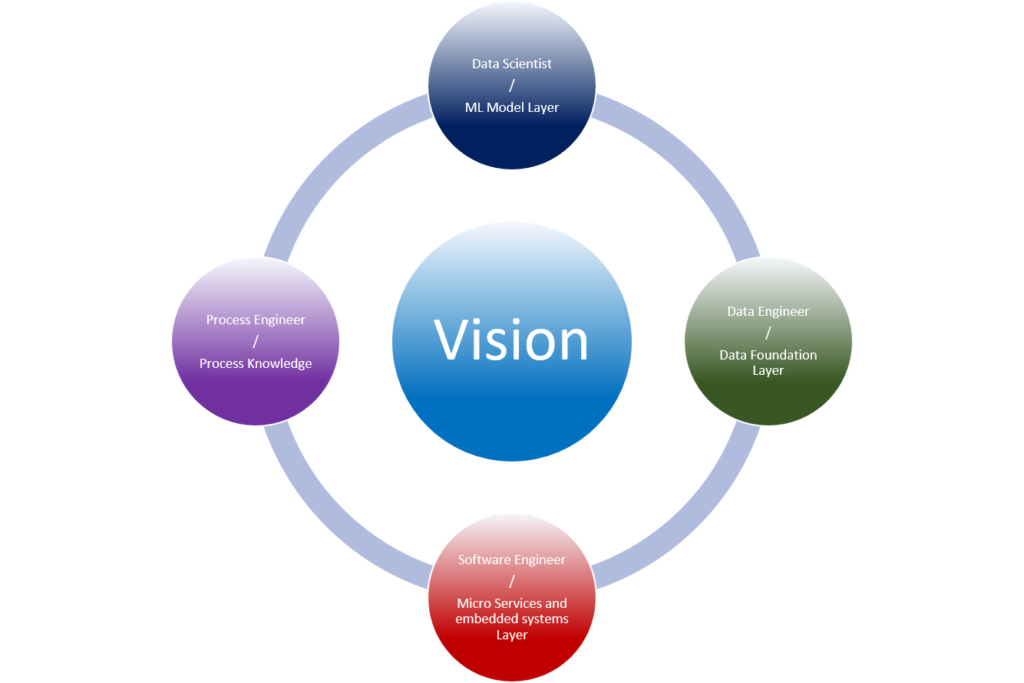
Key take-aways are:
So basically you’ll need a team of data engineers, data scientists, process engineers and software engineers to continuously leverage your data intelligence and spread the vision amongst the organization. Organizations that are capable to do this become ‘smart’ industries.
sAInce.io can help you in establishing this vision. We provide services in data engineering, data science and software engineering in order to build intelligent data systems together with your process experts.
We also build ML model pipelines to automatically deploy ML models as Micro Services or to an Edge Device.
Want to know more?
Get in Touch
Originally I started my career as an expert in OO design and development.
I shifted more than 15 years ago to data warehousing and business intelligence and specialised in big data and data science.
My main interests are in deep learning and big data technologies.
My mission: store, process and deliver data fast, provide insights in data, design ML models and apply them to smart devices.
In my spare time I’m very passionate about Salsa dancing. So much that I performed internationally and that I have my own dance school where I teach LA style salsa.