How to choose a database

What criteria influence our decisions to select one or more databases to support a particular use case? Not every use case requires the same approach. In this blog we give an overview of some of the criteria that should be taken into account when choosing one or more databases. We’ll also discuss the CAP theorem as a tool to enforce discussions on consistency vs avaibility for a particular database.
Database selection criteria
What criteria are important when selecting a particular database system or multiple database systems for different use cases?
 Scalability
Scalability
RDBMS are great. A relational database is self-describing. The schema of the database can be defined with its relations and constraints between rows and tables.
We can rely on the functionality of the relational database (not the application code) to enforce the schema and preserve the referential integrity of the data within the database.
And most of them scale up quite well. However there’s a limit. You can’t scale up horizontally. Only vertically. So if you need unlimited scalability and you build an application for growth, you’ll need horizontal scalability at some point.
Vendors like Oracle and IBM did tremendous efforts in the last decade to scale-up their RDBMS to high performing and vertically scaled hardware appliances like Oracle EXADATA and IBM Pure Analytics (previously known as Netezza). However, if you wanted to scale up, you needed to buy a bigger hardware appliance. So, scalability is not a plugin functionality.
With horizontal scaling you add new nodes to the cluster of machines that run your database system and you scale up accordingly. Extra power, extra memory, extra disk space. With a couple of clicks you’re done (if cloud-based).
 Availability
Availability
Do we want our data available 24/7, no matter what happens? In that case we need a database system capable of replicating amongst different physical locations and that can switch over in a second from one master to another master.
Or do we tolerate some unavailability? Then potentially a master/slave system will be adequate for the task.
 Consistency
Consistency
Consistency is one of the key elements of ACID compliance. ACID stands for Atomic, Consistent, Isolated and Durable.
ACID intends to guarantee data validity despite errors, power failures, and other defects. In the context of database, a sequence of database operations that satisfies the ACID properties (which can be perceived as a single logical operation on the data) is called a transaction.
- Atomicity guarantees that each transaction is treated as a single unit. It either succeeds completely or fails completely.
- Consistency means that a transaction can only bring the database from one valid state to another. It will adhere to all constraints and relations implemented by the database. This prevents data corruption by an illegal transaction.
- Isolation ensures that concurrent execution of transactions leaves the database in the same state that would have been obtained if the transactions were executed sequentially. Isolation is the main goal of concurrency control.
- Durability guarantees that once a transaction has been committed, it will remain committed even in the case of a system failure.
An example in the RDBMS world
Consider a scenario where you have one database server in Europe and one in the US. Both are kept in sync. Users in Europe use the server located in Europe, and users in the US use the server located in the US. Makes sense.
But suppose there’s a breakdown in the communication between both servers. We want to provide consistency in the data. Do we deny updates in both systems so all data remains consistent? Or do we use one of them as the system of truth (the master) and have all users pointing to that system? Users can continue to read and write data but when the communication is restored we’ll need to bring both systems in sync again. As a result, both systems will be eventually consistent.
Or do we sacrify consistency and have both systems up-and-running, applying updates and try to merge the updates later on when the communication has been restored?
An example in the NoSQL world
An analogous reasoning applies to distributed data: NoSQL databases are inherently capable of distributing and replicating data amongst different nodes. How then to deal with consistency? Do we wait until all nodes have confirmed the transaction or do we apply a certain quorum?
Hence do we need immediate consistency or eventual consistency? In a lot of use cases it’s ok to have eventual consistency.
For instance, Amazon DynamoDB, a well-known key-value store, by default provides eventual consistency for writes and reads, hence giving up consistency for the sake of availability.
However, it is possible to opt for strong consistent reads (not writes – writes are always eventually consistent in Amazon DynamoDB) giving up on availability. Strong consistent reads will return an error in the case of a network delay or network outage if the read doesn’t succeed.
In Cassandra, a well-known wide-column store, you can completely configure how consistency will be dealt with: this is based upon the chosen consistency level and the number of replicas in the cluster. By default Cassandra also gives up consistency for availability and if the system writes the data to one replica, it considers the transaction as complete. However it is possible to opt for higher consistency and sacrifice availability by enforcing that all replica nodes for a single partition have confirmed the write before completing the transaction. Cassandra then provides a broad spectrum of intermediate consistency levels by tuning the consistency configuration.
 Flexibility
Flexibility
In some cases we don’t want to be limited to a strict schema and we want to be flexible in the structure of our data. In such a case we probably love JSON (Javascript Object Notation) and would love to use a database system that can natively store JSON objects. Maybe we want the system to adhere to a certain JSON schema when querying data etc.
But we want that flexibility of storing our data in any structure we want.
Object stores (a.k.a. document-oriented stores) provide such functionality. Examples are MongoDB and CosmosDB.
Or maybe we want a system that can bring us a strict schema like in the RDBMS world and at the same time some flexibility where we can bypass that strict schema. In such a case we would like to opt for a kind of hybrid DBMS like PostgresQL. PostgresQL is at his core Relational in nature but provides very powerfull functionalities extending the relational heart with JSON support for instance.
 Fast performance
Fast performance
The times when users were ok with +10 seconds of delay before the system provides any response are long gone. Nowadays we want fast retrieval of data and/or fast ingestion of data. Depending on the use case, we’ll select one or another database system.
In some cases we need microsecond response times which cannot be achieved by using merely disk I/O. In those cases we need an in-memory database that provides datasets that we can leverage through RAM-intensive storage.
 Type of data
Type of data
What kind of data are we going to store? Time-series data have different requirements than bill of materials data or customer data etc.
IoT timeseries data in general don’t require updates but fast ingestion and retrieval. If we would have to capture all relations about our Facebook friends and their relations we also have a different requirement. We want to navigate fast from one node to another and this amongst all our potential friends in the world!
So the type of data that we want to store and the type of queries that we need to provide on those data will have an impact on our choice of database.
 Maintenance and support
Maintenance and support
Do we want to outsource maintenance and support of our databases to an external company? Are we going to provide our own infrastructure on-premise or host the system on cloud infrastructure?
Supporting the database system(s) on-Premise also comes with a cost: cost of training for our IT employees, pure hardware costs, licencing etc.
The same applies when we want to scale-up on-premise. We need to extend the infrastructure and configure our database systems to extend its scale dynamically. This in contrast to cloud-infrastructure where extension is an action of minutes and that occurs without any downtime.
Databases and the CAP theorem
The dilemma
The CAP theorem, a computer technology theory developed originally by Eric Brewer, states that a distributed computer system cannot guarantee the optimal state of all 3 of the following criteria:
- Consistency
- Availability
- Partition Tolerance
Optimal consistency means that in the system at all times the same state is present. Hence all clients have the same view on the same state at all times. This means that every read receives the most recent write or an error.
Optimal availability means that the system exists and that updates can be performed at all times. Hence there is no downtime. Every request receives a (non-error) response, without the guarantee that it contains the most recent write.
Optimal partition tolerance means that if a system exists of n parts (also referred to as partitions), it remains working in n parts if the communication between the n parts gets broken. The system continues to operate despite an arbitrary number of messages being dropped (or delayed) by the network between nodes.
The CAP theorem implies that in the presence of a network partition, one has to choose between consistency and availability.
Hence when a network partition failure happens should we decide to
- Cancel the operation and thus decrease the availability but ensure consistency
- Proceed with the operation and thus provide availability but risk inconsistency
The CAP theorem applied
Sometimes the CAP theorem is used to display how database solutions compare to this triangle. This can be a bit misleading as most database systems actually have different configurations to sacrifice either availability either consistency.
In the latter context it has actually a lot of value.
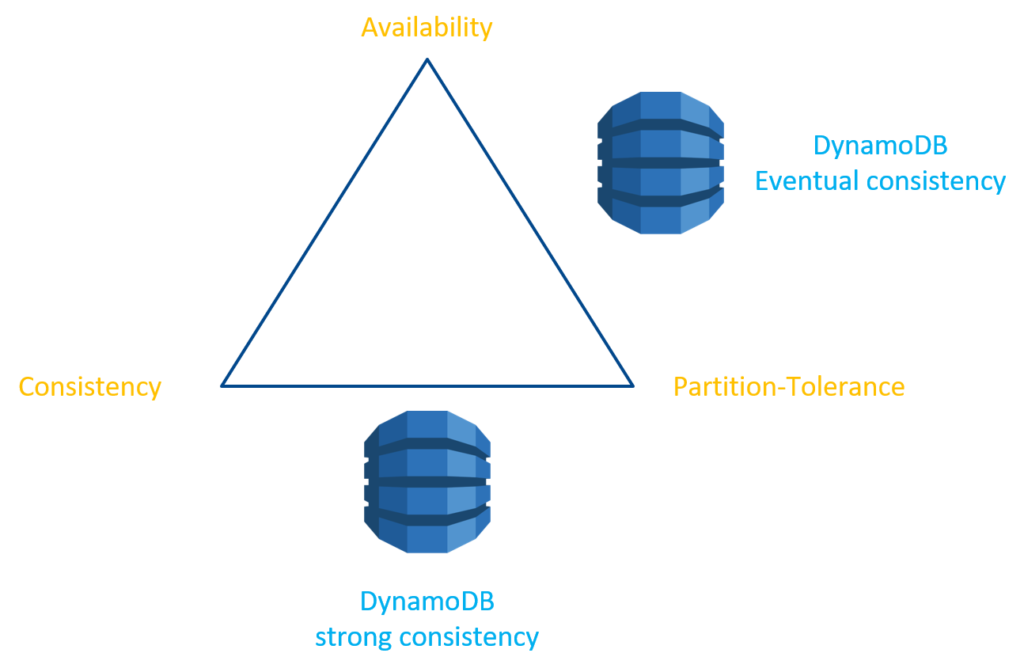
Here we position the different consistency configurations applicable to DynamoDB as mentioned before.
The CAP-triangle is hence an interesting tool to help figure out the different configurations one has with respect to a particular database.
Recap
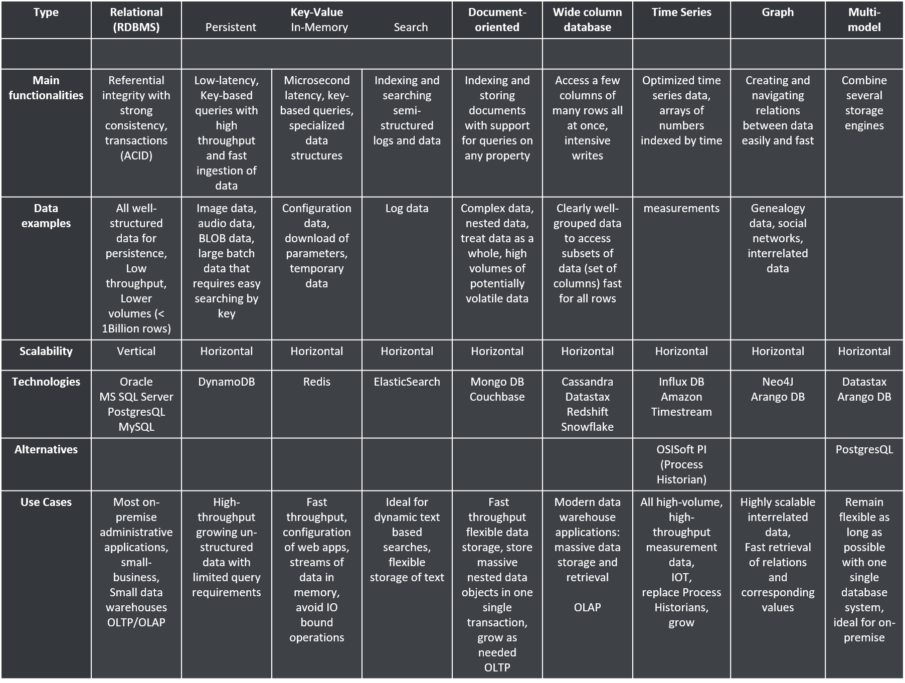
Let’s revisit the table we applied before in our blog on NoSQL databases and extend it with some examples of applicable use cases. You can use this table as a kind of general guidance. However, as said before, each use case should be dealt with with its specific requirements in mind. Complete the below table with the selection criteria mentioned above and you’ll have a well-funded approach to start selecting the database for your needs.
Conclusion
Comparing one database solution with another database solution requires understanding the actual data needs and how this data will grow over time. In addition availability, consistency and partition tolerance help to discuss and design a solution from a technical perspective and make the right choice.
Key take-aways:
Know your data when choosing a database. Incorporate scalability, consistency, flexibility and performance requirements to make the right decision.
Use the CAP triangle to discuss the balance between consistency and availability in distributed systems. Know what you opt for upfront.
Want to know more?
Get in Touch
Originally I started my career as an expert in OO design and development.
I shifted more than 15 years ago to data warehousing and business intelligence and specialised in big data and data science.
My main interests are in deep learning and big data technologies.
My mission: store, process and deliver data fast, provide insights in data, design ML models and apply them to smart devices.
In my spare time I’m very passionate about Salsa dancing. So much that I performed internationally and that I have my own dance school where I teach LA style salsa.