The NoSQL landscape

Gone are the days that we stored our data only in Relational Database Management Systems (RDBMS). RDBMS have been on the forefront of every Operational and Business Intelligence system in the past. Not anymore. Nowadays we have to deal with multiple types of NoSQL databases. In this blog we’ll give an overview of all the different kinds of databases out there.
NoSQL
Traditionally RDBMS come with support for Structured Query Language (SQL). More about half a century SQL is and has been the default standard to execute queries on databases, add and modify data, etc.
NoSQL means Not Only SQL. To deal with the high amounts of data we process nowadays alternative types of databases emerged. Companies like Google, Amazon and Facebook, just to name a few, developed other database systems than our well-known RDBMS.
A lot of these database systems have been open-sourced leading to a wide variety of powerfull database systems that can actually process todays big data requirements. Of course most of these database systems have a fully open-source community edition and a payable enterprise version.
One ring to rule them all?
Why do we have all these different types of databases? Because, as Vogels said:

“A one size fits all database doesn’t fit anyone”
— Werner Vogels, CTO of Amazon
Applications require sound architectures. We want them to scale effectively. And we know that there will always be somewhere a monkey inducing chaos amongst our infrastructure. Hence design for failure is a must!
Apart from technical requirements we have different functional requirements when we want to develop a web application, an IoT solution or a Data Warehouse. And maybe we want that our system is available all over the world so our customers can buy from everywhere around the globe, with split-second response from our system.
In contrast to the one-ring of Lord Sauron, there’s not a single database that captures all use cases and requirements that we need for our applications.
Different types of databases
So let’s have a look at different types of databases and which use cases they will fit.
 RDBMS databases
RDBMS databases
The first RDBMS systems emerged in the late 70s of the previous century with Oracle being one of the first big vendors providing a RDBMS system. Later on IBM DB2, Informix and other vendors followed. Most known RDBMS databases today are Oracle, Microsoft SQL Server, PostgresQL, MySQL and IBM DB2.
The Relational model
In a RDMBS system we organize data in one or more tables. Each table exists of columns and rows with a unique key identifying each row. We call those rows records and those keys primary keys. Each table represents an entity type such as customer or product. The rows represent instances of that type of entity and the columns represent values attributed to that instance (such as name or unit price).
Rows in a table can be linked to rows in other tables by adding a column for the unique key of the linked row. We call these foreign keys. Apart from keys we can also define unique indices to add additional constraints to the database and we can use standard indices for faster retrieval of data. Those indices are usually implemented through some sort of B-trees, R-trees or bitmaps.
Most RDBMS systems also provide the concept of Stored Procedures: in essence this is executable code stored in the RDBMS database. Also the concept of views is supported: in essence this is a query stored in the RDBMS database and that will be executed at the moment one queries the view. A materialized view on the other hand is a kind of snapshot of an executed query that is stored internally as a kind of table. Refreshing such a materialized view actually means re-executing the underlying query (like in a view) and storing the results in a snapshot table (unlike a common view).
RDBMS databases are inherently ACID-compliant. Every modification on data will transfer the database from one consistent state to another consistent state.
All RDBMS systems support SQL: Structured Query Language. This query language became an international standard in 1987 and has been evolved over time providing powerfull features. Although not all RDBMS apply the same ‘flavour’ of SQL, most of them all support the standard SQL operations.
SQL consists of 4 parts:
- DQL: data control language to control access to data stored in the database (e.g. grant, revoke)
- DQL: data query language to perform queries on the data in the database (e.g. select)
- DML: data manipulation language to add, delete or modify data in the database (e.g. insert, update, delete)
- DDL: data definition language to create and modify database objects in the database like tables or indices etc. (e.g. create, drop)
Modeling paradigms in RDBMS
Apart from the standard organization of the data in tables, columns and rows we also have different modeling paradigms for RDBMS.
With normalization we try to minimize the redundancy (duplication) of data. This prevents data manipulation anomalies and loss of data integrity and has been the de-facto standard for OLTP (Online Transactional Processing) databases. So whenever we build a system that requires heavy input from users, normalization of the data structure is a must.
With denormalization we try to minimize the amount of joins required to retrieve data. This prevents heavy query operations and is mainly targeted to optimize querying. This modeling paradigm is mainly used for data warehouses and reporting databases and supports OLAP (Online Analytical Processing) databases. In data warehousing we mostly apply the concept of star schema where data is split in 2 types of tables: facts containing all measure data and dimensions containing all data on a specific axis (time, customer, product) that you would use to query or analyse the system.
Since OLTP and OLAP have completely different use cases we can’t apply them in most cases on one single database. That’s the main reason why in RDBMS systems we need to offload data from OLTP databases to a central OLAP database in order to support the organizational OLTP and OLAP needs.
This led to quite some latency in analytical processing of data since traditionally it requires specific design strategies to be able to offload and transform data from an OLTP database and normalized structure to an OLAP database and denormalized structure. Most data warehouses still use the concept of day-1 data availability.
With technologies like CDC (Change Data Capture) that continuously replicate data from the OLTP database to the OLAP database we can eliminate the latency due to the required offloading of data from the OLTP system. However, we can’t eliminate the transformation processing required to transform the normalized to a denormalized structure. Since the amount of data passing through the CDC ‘hub’ is however much less than if we were to perform a one-time-per-day load, the transformation process will be faster. It requires a well-thought design to incorporate all required relations. Multiple techniques exist to design such a proper load mechanism, balancing out on the consistency criteria previously mentioned.
 Key-value databases
Key-value databases
The Key-Value data model
A key-value database is a NoSQL data storage designed to store, retrieve and manage a data structure better known as a dictionary. Dictionaries contain objects that can have multiple fields each containing data. Each object is stored and retrieved using a key that uniquely identifies the object. Examples of key-value databases are Amazon DynamoDB and REdis.
In a key-value database, every entity is a set of key-value pairs. In contrast to RDBMS databases, objects (or records) in a key-value database may have different fields for each record. This provides tremendous flexibility and conforms more to modern concepts like object-oriented programming.
In addition, optional attributes are in general not stored in a key-value database and hence they tend to use less memory to store the same data as opposed to RDMBS databases.
Key-value databases can use different consistency models (e.g. eventual consistency) and some maintain data in memory (RAM) while others use solid-state drives or rotating disks.
Most key-value stores are also distributed or ‘sharded’. This means that they are specifically designed to enable horizontal scaling instead of vertical scaling and can be extended with additional ‘shards’ to store more data. Sharding data however brings back the question of consistency and decisions will need to be taken on how to apply which consistency model.
In a true key-value store queries can only be done through the key or through components of the key. It is not possible to query directly on the contents of the value or create complex queries on the data contents.
That’s where object stores a.k.a. document-oriented databases come in. They are a special kind of key-value stores that extend the functionality of a pure key-value store with additional powerfull query capabilities on the content of the data.
As said before, there’s no 1 ring to rule them all: it all depends on the use case.
While key-value databases are powerful, there’s no standard like with RDBMS databases and each kind of key-value database is designed differently to cope with multiple requirements.
We’ll dig deeper into the realms of key-value stores with our blogs on Amazon DynamoDB and Redis.
 Object / Document-oriented databases
Object / Document-oriented databases
Document-oriented databases are actually specialized key-value stores. Examples of NoSQL document-oriented databases are MongoDB, Microsoft Azure CosmosDB and Couchbase.
We call these databases document-oriented, not because they contain documents like pdfs or word documents but because they fully support a document-like format. Full-fledged document-oriented databases dispose of powerful query capabilities which sets them apart from the previously mentioned key-value stores.
The central concept of a document-oriented database is the notion of a document or object. Documents encapsulate and encode data in some standard format or encoding. Encodings frequently encountered are XML, YAML, JSON as well as binary forms like BSON.
The flexible, semistructured, and hierarchical nature of documents and document-oriented databases allows them to evolve with applications’ needs.
Objects in a document-oriented database are not required to adhere to a standard schema, nor will they have all the same sections, properties or keys. Generally, programs using objects have many different types of objects, and those objects often have many optional fields. Every object, even those of the same class, can look very different. Document stores are similar in that they allow different types of documents in a single store and allow the fields within them to be optional. Even multiple encodings are possible for the same class so that one object could be stored in JSON encoding while another could be stored in XML encoding.
We’ll go deeper into the specifics of document-oriented database in our blogs on MongoDB and Couchbase.
 Wide column databases
Wide column databases
A wide column database uses tables, rows, and columns, but unlike a RDBMS, the names and format of the columns can vary from row to row in the same table. A wide-column store can be interpreted as a two-dimensional key-value store. Examples of NoSQL wide column databases are Cassandra, Datastax, Amazon Redshift and Snowflake.
In genuine column-oriented databases a columnar data layout is adopted such that each column is stored separately on disk. Wide-column databases often support the notion of column families that are stored separately but do not necessarily store each column separately on disk.
However, each such column family typically contains multiple columns that are used together, similar to traditional relational database tables. Within a given column family, all data is stored in a row-by-row fashion, such that the columns for a given row are stored together.
Wide column databases are well suited for data where applications need to access a few columns of many rows all at once and lend themselves very well for OLAP applications. That’s also the reason why Amazon Redshift and Snowflake are considered modern data warehouse databases.
We’ll focus on Cassandra and Amazon Redshift for this type of NoSQL databases.
 Time-series databases
Time-series databases
Timeseries databases were developed to suit particular use cases with respect to storing and analyzing time-series data. They can efficiently store measured values from sensory equipment but can be used in a much wider range of applications (e.g. stock market monitoring). Examples of these NoSQL databases are InfluxDB, Amazon Timestream and Prometheus.
Most time-series databases will use compression algorithms to manage data efficiently or use retention periods and aggregation of data.
In a time-series database discrete characteristics are typically separated from the dynamic continuous values of measurements. An example is the storage of CPU utilization: discrete characteristics are the name (CPU utilization), unit of measure (%) and its range (0 – 100), and the dynamic values are timestamp and the actual percentage measured.
This separation is intented to store and index data efficiently. Most time-series databases also provide functions like calculations, interpolation, filtering and analysing time series data.
In addition, true NoSQL time series databases are designed to scale vertically and to provide high-throughput while maintaining high performance for analytics.
This in contrast to Process Historians like e.g. OSISoft PI which can only scale horizontally. Process Historians are proprietary products that have been around for decades to store measurements from industrial equipment.
Historians were the traditional choice to store equipment measurements and have high compatibility with industrial software such as HMIs, PLCs, OPC drivers etc. They also support store and forward capabilities that guarantee no data loss. However the full potential of the data stored in these Process Historians has largely been unrealised. One of the reasons being that it is quite difficult to provide context to the data. We’ll provide some interesting insights in how to unlock these data in our blog on Historian Augmentation.
With respect to time series databases, we’ll discuss InfluxDB and Amazon Timestream.
 Graph databases
Graph databases
Graph databases are purpose-built to store and navigate relationships. They use nodes to store data entities and edges to store relationships between entities. Examples of such NoSQL databases are Neo4J, ArangoDB and Amazon Neptune.
An edge always has a start node, end node, type, and direction. An edge can describe parent-child relationships, actions, ownership, and the like. There is no limit to the number and kind of relationships a node can have.
A graph in a graph database can be traversed along specific edge types or across the entire graph. In graph databases, traversing the joins or relationships is very fast because the relationships between nodes are not calculated at query times but are persisted in the database.
These databases have advantages for use cases such as social networking, recommendation engines, and any system where you need to create relationships between data and quickly query these relationships.
We’ll provide more insights on Neo4J and Amazon Neptune in our blogs.
 Search databases
Search databases
A NoSQL search-engine database is a type of nonrelational database that is dedicated to the search of data content. Search-engine databases use indexes to categorize the similar characteristics among data and facilitate search capability. Search-engine databases are optimized for dealing with data that may be long, semistructured, or unstructured. They typically offer specialized methods such as full-text search, complex search expressions, and ranking of search results.
They are often used in combination with other databases to provide fast search capabilities in stored content.
We’ll have a look at the internals of Elasticsearch.
Summary of databases
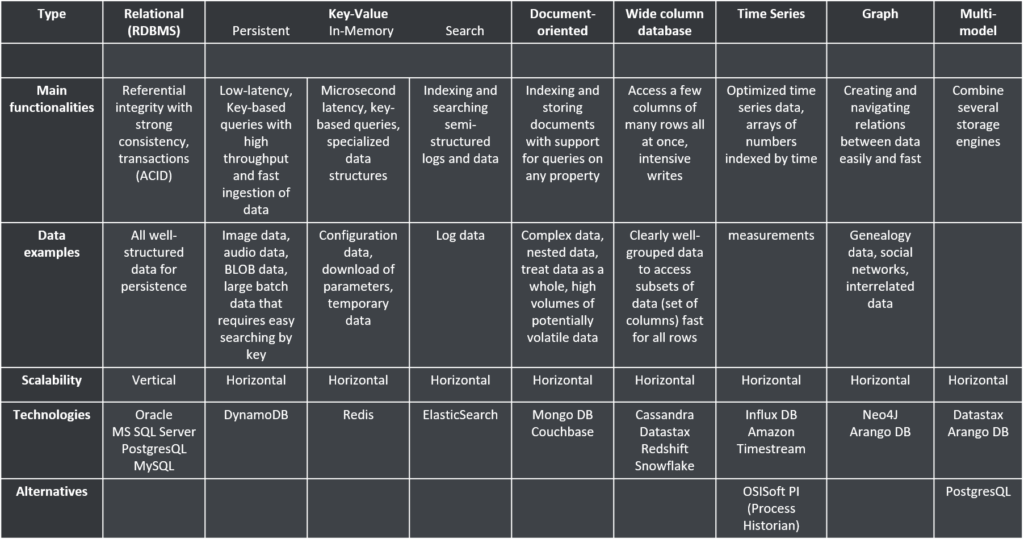
Let’s have a short summary of all these database types. The following table provides an overview of available NoSQL databases (next to the RDBMS systems) and how we can apply those NoSQL databases. Apart from the Amazon databases which are only available in the cloud most of them are available as well on-premise as in the cloud. We’ll extend this table later with applicable use cases in our blog “How to choose a database”.
Conclusion
There’s not one database that will fit all your use cases and this for multiple reasons. Not all data is the same and in a lot of cases we need to provide a tailored solution. It is worthwhile to have a good understanding of the different types of databases that are available on the market and that we can setup for our particular use cases.
Key take-aways:
NoSQL databases have merited their place next to RDBMS systems for a variety of use cases. NoSQL databases can give you an edge when dealing with semi-structured or non-structured data and when dealing with platforms that need to be horizontally scalable and available 24h 7.
Want to know more?
Get in Touch
Originally I started my career as an expert in OO design and development.
I shifted more than 15 years ago to data warehousing and business intelligence and specialised in big data and data science.
My main interests are in deep learning and big data technologies.
My mission: store, process and deliver data fast, provide insights in data, design ML models and apply them to smart devices.
In my spare time I’m very passionate about Salsa dancing. So much that I performed internationally and that I have my own dance school where I teach LA style salsa.