SingleStore – the one ring to rule them all?

In a previous blog (The NoSQL landscape) we discussed multiple NoSQL databases and technologies. We strongly believe in a mixture of database technologies to support various use cases… As Vogels said:

“A one size fits all database doesn’t fit anyone”
— Werner Vogels, CTO of Amazon
And we still agree that depending on the use case, a particular type of NoSQL or SQL could be the best fit. However, recently we came accross SingleStore in one of our projects and started to doubt the above quote. Could there really be a database technology that is able to support so many use cases that you could rely on that one single technology in your enterprise?
A star is born
Previously known as MemSQL, SingleStore was born as not only a rebranding of MemSQL but also to reflect a shift in focus away from exclusively in-memory workloads. And although sceptical at first, we were impressed by its capabilities. SingleStore is not only a database system. It is a full database platform that supports as well transactional as analytical use cases. Truly, how lord Sauron managed to forge this technology in mount Doom is unclear to us. But somehow it happened. The one ring is here.
SingleStore is ANSI SQL-Compatible and natively supports structured, semi-structured and unstructured (full-text search) data. With built-in connectors to Kafka, Spark, S3, and Hadoop, as well as legacy transactional systems, SingleStore easily integrates with a broad ecosystem to cover both real-time streaming and batch workloads.
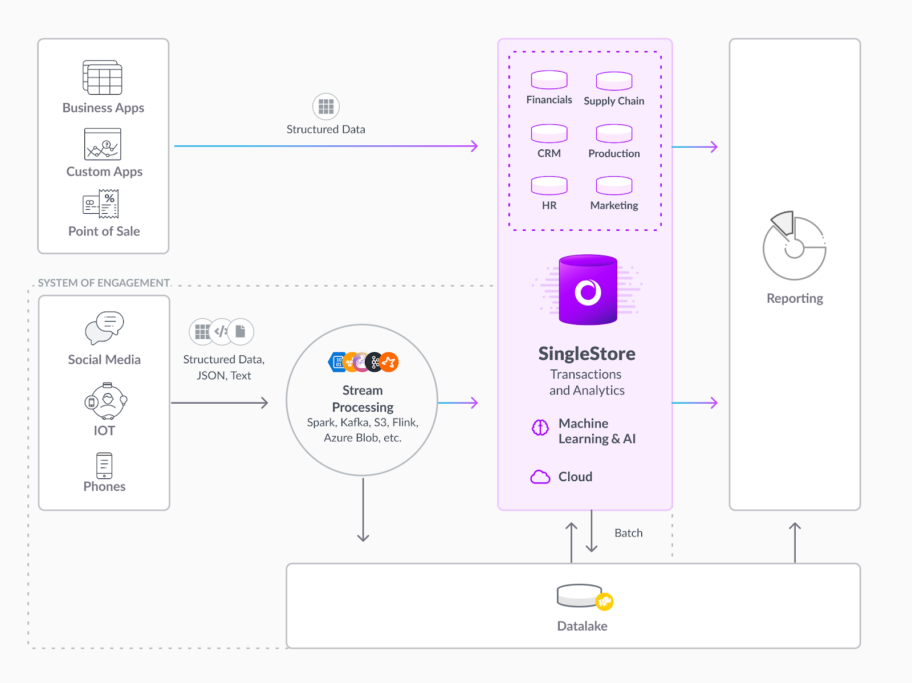
It natively supports rowstore data, columnstore data, JSON data, time-series data, geo-spatial, key/value data etc. on a single platform with the ease and familiarity of SQL.
With SingleStore, all enterprise features, such as partitioning, security, high availability (HA), and disaster recovery (DR), are included in the product and not licensed separately.
And it’s fast, bloody fast. And it’s available in the cloud and on-premise. It seems to check all the tickboxes. Indeed, we are impressed. SingleStore is here to stay and we’re pretty sure it will land in a lot of companies and can become one of the main database technologies used around the globe. We can imagine a world where the de facto standard becomes a technology like SingleStore, only to be extended with some extra storage technologies to build a full eco-system. But yes, we believe that the heart could be SingleStore.
Built for speed and concurrency in a distributed environment
SingleStore embeds an industrial compiler (LLVM) which incrementally compiles just-in-time execution plans written in C++ to machine code. Compiled plans are cached as well in-memory as on-disk (depending on expiration) optimizing as such for query speed. By interpreting SQL statements and implementing compiled query plans, SingleStore removes interpretation overhead and minimizes code execution paths.
SingleStore also uses lock-free data structures including queues, stacks, hash tables, skip lists, and linked lists to perform well in-memory and under high concurrency, thereby delivering better scalability.
In addition SingleStore uses Multi-Version Concurrency Control (MVCC) to prevent queries from blocking each other in multi-threaded applications, hence favouring parallellism. Today’s real-time applications – especially those with high volumes of streaming data, or mixed read and write workloads – cannot tolerate the performance loss that comes with database locking.
By using MVCC SingleStore avoids locking on both reads and writes when updating tables. As a result, writes can operate at greater throughput, while a large number of concurrent reads happen simultaneously. Since reads and writes never block one another, this minimizes query stalls and allows for greater parallelism enabling maximum concurrency.
SingleStore provides disk-optimized columnstore tables and memory-optimized rowstore tables. Rowstores and columnstores differ both in storage format (row vs. column) and in storage medium (RAM vs Disk). SingleStore allows querying rowstore and columnstore data together in the same query.
The rowstore is typically used for highly concurrent online transaction processing (OLTP) and mixed OLTP/analytical workloads. SingleStore’s disk-based columnstore features up to 80% compression and is capable of storing petabytes of data. Columnstores are optimized for complex queries over large data sets that don’t fit in memory.
Since version 7.5 SingleStore however supports what they call Universal Storage: the columnstore in SingleStore uses actually a 3-tier architecture that uses as well rowstore features (in memory), classic column storage on disk and can even leverage object storage.
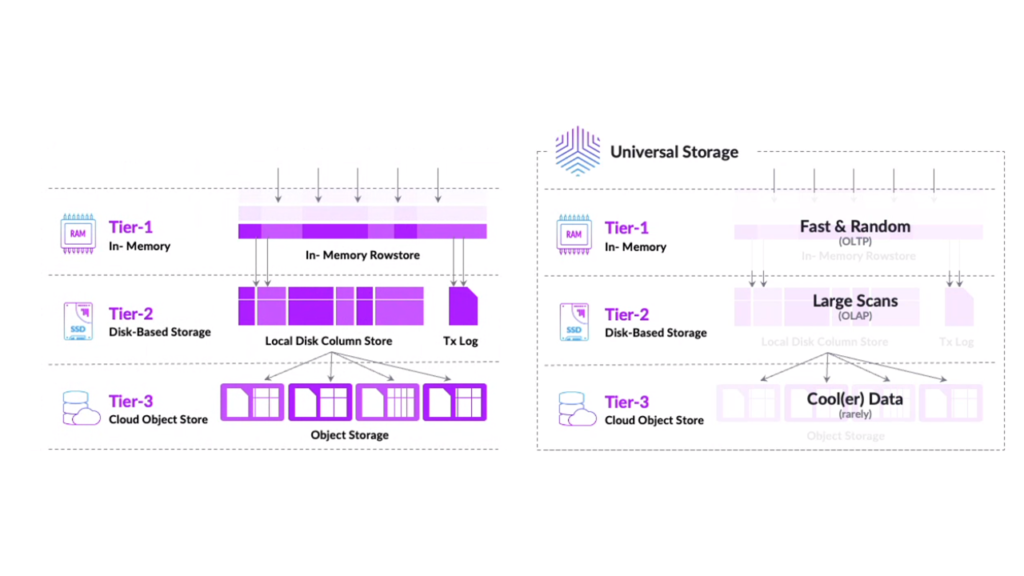
The first tier consists of the In-Memory Rowstore and provides extremely fast random reads and writes. Row lookups are in sub-milliseconds.
The second tier consists of the On Disk Columnstore which is scalable with high compression. It is not impacted by slow data entry and is immediately available for fast analytical queries.
The third tier consists of Object Storage and provides durability. It delivers unlimited storage capacity for bulk data storage and up to 90% compression. All data is asynchronously written to object storage.
You can still create a pure rowstore table but the default table format in SingleStore is columnstore and actually means universal store which fully supports hot, warm and cold data.
SingleStore also supports fast distributed query processing, with a query optimizer that is fully aware of data distribution, and a query execution system that takes advantage of compilation and vectorization. The optimizer can use broadcast, shuffle, local-global aggregation, semi-join reduction, and co-located join operations and uses data movement across the cluster judiciously.
SingleStore’s Core Architecture
SingleStore utilizes a distributed, shared-nothing architecture that runs on a cluster of servers, and leverages memory and disk infrastructure for high throughput on concurrent workloads. No two nodes in a SingleStore cluster share CPU, memory, or disk. It’s architecture is built for horizontal scalability on commodity hardware on-premise or in the cloud.
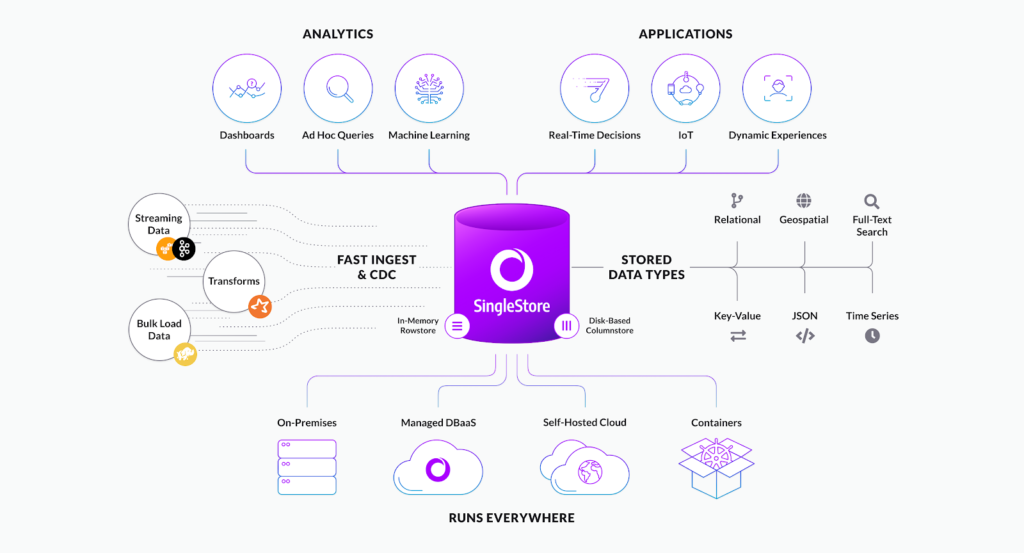
A SingleStore cluster consists of aggregator nodes and leaf nodes. The aggregator serves as a query interceptor and router, manages cluster metadata and is responsible for cluster monitoring and failover. A leaf node is a SingleStore server instance that stores data and executes queries issued by the aggregator.
In typical deployments, the aggregator-to-leaf node ratio is generally 1:5. Increasing the number of aggregators can improve operations like data loading and can allow for SingleStore to process more client requests concurrently. Applications serving many clients have a higher aggregator-to-leaf ratio, and those with more demanding storage requirements need more leaves per aggregator.
When a database is created in SingleStore, it is always partitioned. Partitions reside on the leaf nodes. When a sharded table is created, it is split according to the number of partitions of its encapsulating database. Each partition will hold a slice of the table. In a database Demo with 4 leaf nodes and 8 partitions this would result in a distribution of the table data amongst all 8 partitions (HA/Replication not taken into account).
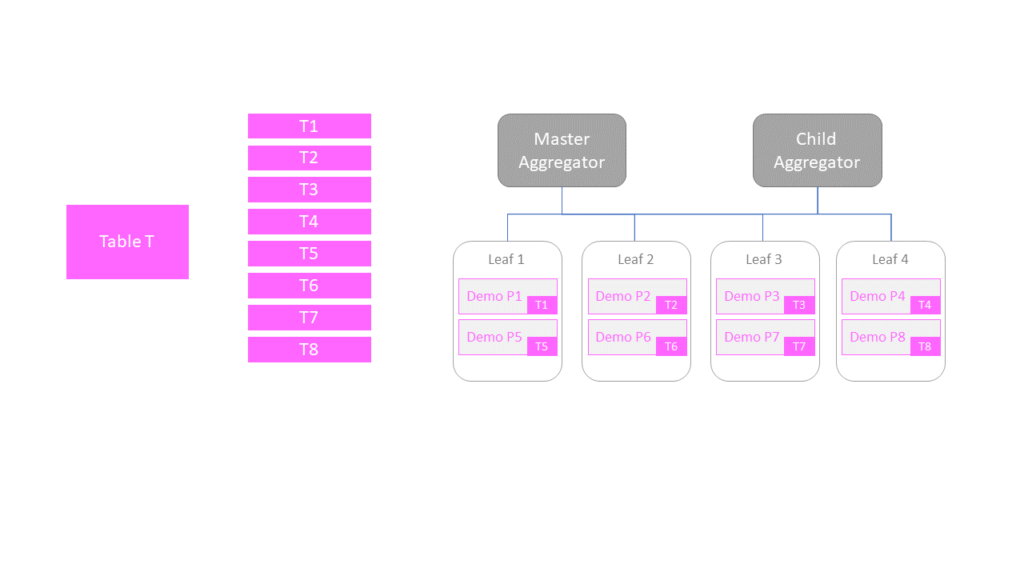
SingleStore supports both distributed (or sharded) and reference (or duplicated) tables. Both table formats can be as rowstore or columnstore tables. For sharded tables, the primary key acts as the hash and each shard is stored on the respective leaf nodes. For reference tables, the table is replicated to all nodes (including aggregators) and is well suited for smaller, slowly changing tables. Since reference tables are available on all the leaf nodes joins with these tables occur of course at high speed. It remains of course of primary importance to design sharded keys for distributed tables according to best practices and to minimize data shuffling.
SingleStore Pipelines is a built-in feature that ingests data from external sources in a continuous manner. As a built-in component of the database platform, Pipelines can extract, transform, and load external data without the need for third-party tools or middleware. Through Pipelines data is loaded in parallel from the data source to SingleStore leaves, which improves throughput by bypassing the aggregator. Pipelines are available for parallel ingestion of kafka streams, hdfs, S3 files and so on.
Built for growth
SingleStore’s distributed system allows clusters to be scaled out at any time to provide increased storage capacity and processing power. Sharding occurs automatically and the cluster re-balances data and workload distribution. Data remains highly available and nodes can go down with little effect on performance. As Data is distributed and the cluster is self-healing and elastic, it allows for scale-out/in data processing.
SingleStore supports dynamic cluster operations. You can add or remove nodes – leaves or aggregators – to the cluster at any time while keeping the cluster online, even while running a workload.
A SingleStore cluster is resilient to failure with automatic failover and self-healing capabilities. SingleStore allows you to store a redundant copy of data within a cluster. Leaf nodes are organized into availability groups such that each node is paired with a node in the other availability group. Each leaf node has a pair that replicates its data, and can be configured to do so synchronously or asynchronously. In case of node failure, SingleStore restores data and promotes replica partitions to put the cluster back online.
Secure
Security is an important aspect of any data platform. To meet regulatory and compliance requirements, SingleStore supports several security features in the areas of authentication, authorization, auditing, and encryption.
Existing account access can be easily managed via PAM (Pluggable Authentication Module), SAML, or GSSAPI (Kerberos) authentication support. SingleStore also implements RBAC to protect sensitive data for tens of thousands of distinct users and their specific access roles.
And its future?
SingleStore definitely acquired a fan here. We are completely on-board with this technology and can’t wait for all the analytical and transactional use cases that we’ll be driving with SingleStore. SingleStore is well-designed, built for the future, built to be containerized and deployable on-premise and in-the-cloud. Are there any features we’d like on its roadmap? Yes, of course. We’d love to have External Tables or Dictionaries instead of ingestion on HDFS/S3 etc. and there are a couple of other functionalities on our wishlist but what SingleStore can already deliver today is impressive.
Conclusion
While building your data architecture for the future, it is definitely worthwhile to take SingleStore into account. SingleStore is highly scalable, distributed, fast, supports a various number of data formats, supports multiple storage engines and supports as well transactional as analytical workloads. It can be plugged in into existing architectures quite easily and start to extend and augment current investments. SingleStore is a keeper for sure.
Key take-aways:
SingleStore could well be the one ring to rule them all, supporting transactional and analytical workloads, supporting rowstorage and column storage and accessing unstructured, semi-structured and structured data formats with the ease and familiarity of SQL.
Want to know more?
Check out SingleStore’s website
Check out SingleStore’s blog.
Get in Touch
Originally I started my career as an expert in OO design and development.
I shifted more than 15 years ago to data warehousing and business intelligence and specialised in big data and data science.
My main interests are in deep learning and big data technologies.
My mission: store, process and deliver data fast, provide insights in data, design ML models and apply them to smart devices.
In my spare time I’m very passionate about Salsa dancing. So much that I performed internationally and that I have my own dance school where I teach LA style salsa.