Data Lakes – Reference Architecture

The last decade one of the main buzzwords is Big Data. As usual, a lot of vendors smelled the cookie and suddenly all their products supported in some way ‘Big Data’. This overwhelmed the world with a vast amount of tools and technologies.
The world of Big Data has become very difficult to grasp with all the available products out there, ranging from enhanced Massive Parallel Processing SQL databases to distributed NoSQL databases.
Think about object stores (aka document stores), graph databases and time series databases, data streaming engines and data lakes, distributed file systems and distributed data processing platforms.
Why big data?
We all understand the notion of Big Data. It’s about a huge set of data. But why would we invest in Big Data solutions? When do we need it?
Well, there’s a simple answer.
Because you want to train Machine Learning models and use it for data analytics purposes.
Without a lot of historical data you’re Machine Learning model will underfit and will not be able to perform well. It needs data. A lot of data. And it needs context. It makes no sense to just store pressures and temperatures in a timeseries storage.
Pure storage will not provide us any context. We need to be able to find the correlations between features and detect which parameters have an impact on predictable outcomes.
A data lake also serves Business Intelligence. We can aggregate data, calculate our KPIs and monitor the performance of our factories.
Cloud-native
However, we do not recommend to invest in big data analytics on-Premise. Trying to setup a big data infrastructure requires a lot of investment in not only hardware but also knowledge of the underlying big data stack like Hortonworks, Cloudera, MapR or Databricks, just to name a few.
In addition, still a lot of evolution is going on in the big data world.
No, we recommend you invest in a full cloud or a Virtual Private Cloud environment for your data analytics stack. This enables you also to use some of the state-of-the-art full Cloud platforms like AWS, Azure and Google.
This in contrast to hot data. Hot data is data that you access very frequently and that you need for operational purposes, in most cases also in real-time. That kind of data you probably would like to keep on-Premise.
The big data factory
Let’s zoom in into our factory. We’re definitely interested in our equipment data. We probably want to enrich this data with contextual data like production orders, materials required and materials consumed, scrap, lab data that can have an impact on quality (e.g. pH, lab tests), TIR/TOR (Time in/out refrigerator) data, etc.
And maybe we also want to extend these datasets with the parameters that were used to produce a particular production batch etc.
While the equipment data can come from different sources already, all contextual information must be sourced from different enterprise systems like:
- ERP (Enterprise Resource Planning system)
- MES (Manufacturing Execution System)
- LIMS (Lab Information Management System)
- WMS (Warehouse Management System)
The data lake
The basis of our Big Data architecture is the data lake.
There are actually 2 fundamental aspects of a data lake:
- Data should be made available in a distributed file or object store – hence it doesn’t matter how much data you have – you can always store it since it’s horizontally scalable
- It must be possible to process the data also in a distributed fashion – hence the data lake architecture must support distributed processing of queries, machine learning and so on.
Reference architecture
In this series we’ll present a Reference Data Lake architecture. It’s a blue print that should give you some insight in the way a Data Lake can be constructed.
The reference architecture we propose enables you to load huge data sets to the cloud and transform them in a storage format that can be dealt with by all data science applications and tools. It’s tailored for fast retrieval of data, typically required for data science purposes.
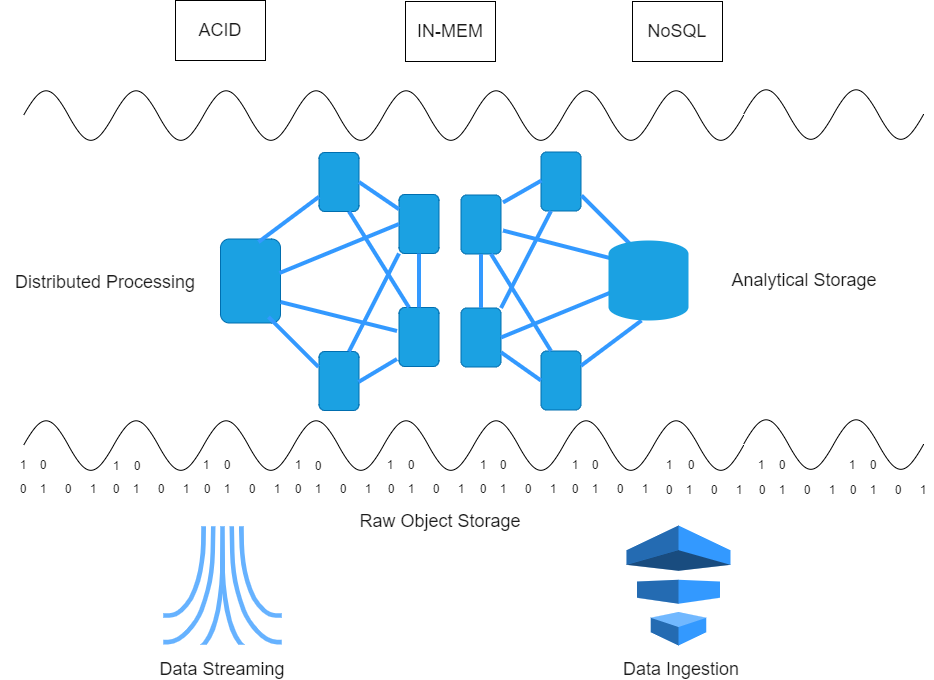
We’ll explain some of the technologies that can be distinguished in each layer of the architecture. Each of the technologies will be discussed in separate blogs in this series.
So let’s review the architecture:
Raw Object Storage – Amazon S3
On the bottom of our reference architecture one can distinguish 2 means of bringing data into the Data Lake.
Data streaming services will provide for a continuous real-time stream of data that enables near-real time data processing in the data lake.
Batch processes will load data according to specific schedules. Most of these batch processing loads can be done through ETL tools or data ingestion tools which we won’t describe in this series. Examples of such tools are Informatica Powercenter, IBM Datastage and Pentaho.
One of the pillars of a data lake is its capability of storing files in a Raw Object Storage. This can be a distributed file system like HDFS, MapR etc. or an object store like AWS S3. We’ll discuss S3 in this blog series.
Analytical File Storage – Apache Parquet
Another important aspect of a data lake is its analytical storage system, in most cases based on the Hadoop Distributed File System, an object store like S3 or a NoSQL database.
Which solution you’ll choose depends on the requirements. In our experience you can start small by leveraging an architecture based on Apache Parquet and an object store/distributed file system before moving towards NoSQL architectures.
It’s also a good practice to first load and transform your data before moving it towards a NoSQL endpoint, at the same time delivering datasets for data scientists to explore and use in their day-to-day tasks.
Distributed Processing – Apache Spark
There’s no data lake without a distributed processing platform: it makes no sense to move to the cloud if you cannot use a cluster of machines to compute and process your big data. We’ll delve deeper into Apache Spark on this topic.
Real-time data streaming – Apache Kafka
Data streaming engines do not only serve on-Premise real-time data processing but also real-time data ingestion. We’ll discuss Apache Kafka.
Additional layers – ACID compliance, In-Memory datasets, NoSQL
Of course you can extend the data lake with additional features like
- ACID compliance, guaranteeing transactional consistency: we’ll get into Delta Lake
- Providing datasets In-Memory: we’ll talk about Dremio
- NoSQL: there’s a lot on this plate but we’ll give you some insights in how to choose one or more NoSQL endpoints
To summarize:
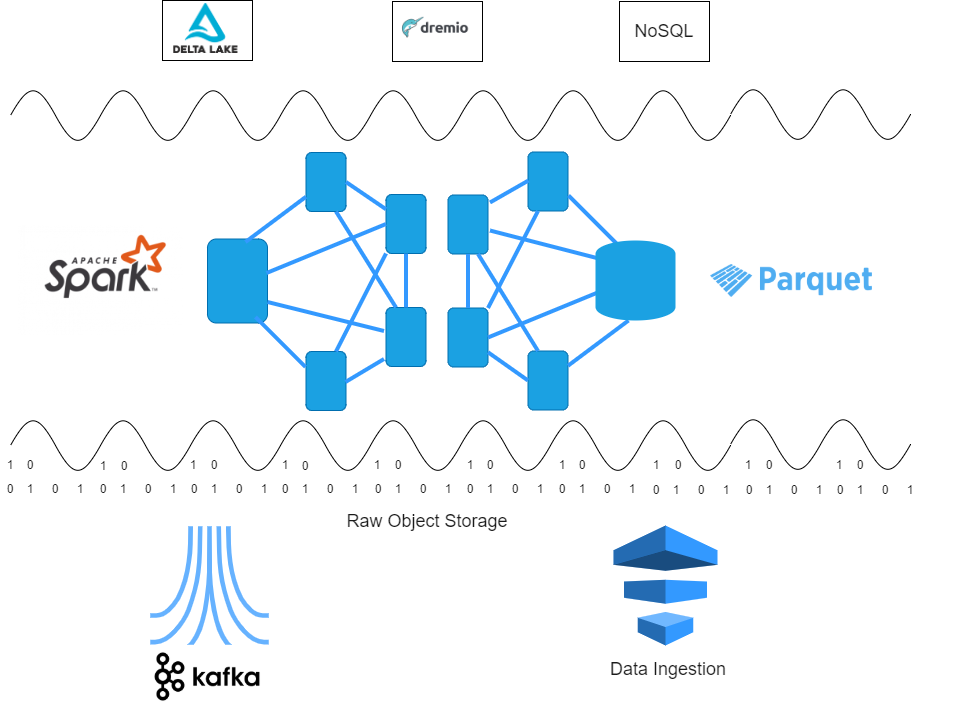
The basic building blocks of our Reference Architecture that we’ll explain in more detail are:
- Raw file or object storage: Amazon S3
- Storage of transformed data on a distributed file system: Apache Parquet
- Distributed data processing: Apache Spark
- Real-time data ingestion: data streaming (e.g. Kafka, AWS Kinesis)
Extensions include:
- ACID compliance for your data lake storage: Delta Lake
- Columnar in-memory provisioning of your data lake: Dremio
- NoSQL as endpoints for as well data science as business intelligence: think about Cloud Data Warehouses and Timeseries databases.
Want to know more?
Get in Touch
Originally I started my career as an expert in OO design and development.
I shifted more than 15 years ago to data warehousing and business intelligence and specialised in big data and data science.
My main interests are in deep learning and big data technologies.
My mission: store, process and deliver data fast, provide insights in data, design ML models and apply them to smart devices.
In my spare time I’m very passionate about Salsa dancing. So much that I performed internationally and that I have my own dance school where I teach LA style salsa.