Data Lakes – Apache Parquet

We love open-source and we believe strongly in the advantages of using open source technologies. In most cases there’s a strong community behind it and the quality of the product or software is generally very high. An example of such open-source software is the Apache Parquet columnar storage format, originally developed at Twitter in collaboration with Cloudera.
Apache Parquet is a data format which embeds the schema, or structure, within the data itself. This results in a file optimized for query performance and minimizing I/O.
Apache Parquet has the following characteristics:
- column-oriented and tailored for efficient columnar storage of data
- supports complex nested data structures
- supports very efficient compression and encoding schemes
- allows to lower storage costs for data files
- maximizes the effectiveness of querying
- completely open-source
Compare this to CSV format which is in essence row-based. Storing data in parquet format will be much cheaper with respect to CSV, even if your CSV files would be compressed with GZIP, since the compression rates possible with Parquet are much higher. In addition, query performance is much higher since Parquet optimizes file scanning.
Columnar Storage
Let’s have a look at a columnar storage and compare it to row-based storage. Traditional SQL databases and csv files store data in a row-based format. Parquet stores data in a hybrid columnar storage.
Suppose you have following nested schema data:
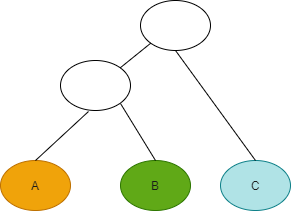
We can represent this data logically in the following table:
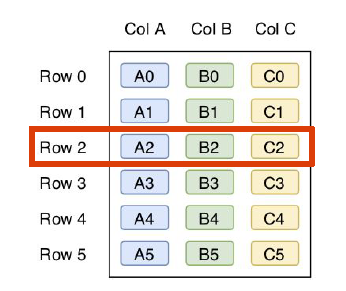
If we look at different physical storage options:
Row Layout

Each row follows the next row and for each row, each column value follows each column value. This means that datatype encoding must be done continuously for each column/row. Partitioning is done horizontally (partitioning row sets).
Pure Columnar Layout
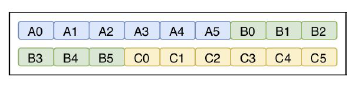
Each column follows the next column. Since all column values proceed each other, datatype encoding can be done once for the full column. Each column is also homogenous. This results also in better compression since compression techniques specific to a type can be applied. Vertical partitioning is straightforward: if we want to partition on specific production batches and one of our columns contains the production batch, it is trivial to partition the data physically by the production batch.
Queries that fetch specific column values do not need to read the entire row data, hence improving performance.
Hybrid Columnar Layout
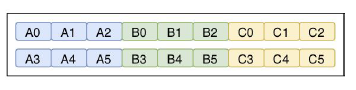
In a hybrid columnar layout columns still follow each other but columns are split in chunks. A hybrid approach enables for as well horizontal as vertical partitioning and hence fast filtering and scanning of data. And it keeps the advantages of homogenous data and the ability to apply specific encoding and compression techniques efficiently.
Apache Parquet
This is actually what Parquet does: it follows a columnar representation but at the same time it splits the data in row groups (default 128Mb) and column chunks. Each column chunk is also split in multiple pages (default 1Mb) containing a.o. metadata (min, max, count), encoded values etc.
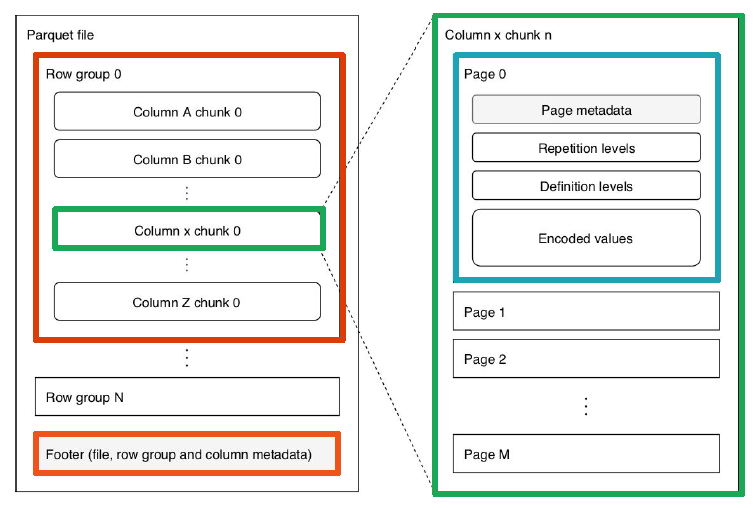
This allows for fast retrieval of data (pick only the data you need) when using partitioning:

This leads to a file format tailored specifically for analytical needs and hence ideal for our Data Lake.
A wide range of analytical tools fully support Parquet. It has become the de-facto standard for file storage on data lakes.
Apply Apache Parquet as file storage medium for large datasets. This will result in high query performance for data science purposes.
You can build further on this by applying for instance Delta Lake instead of pure Parquet but we’ll discuss this in a future blog.
This blog is part of our Data Lake series: Data Lake – Reference Architecture
Want to know more?
Get in Touch
Originally I started my career as an expert in OO design and development.
I shifted more than 15 years ago to data warehousing and business intelligence and specialised in big data and data science.
My main interests are in deep learning and big data technologies.
My mission: store, process and deliver data fast, provide insights in data, design ML models and apply them to smart devices.
In my spare time I’m very passionate about Salsa dancing. So much that I performed internationally and that I have my own dance school where I teach LA style salsa.