Data Lakes – Apache Spark in detail

We already discussed the Spark Ecosystem. In this blog we’ll delve a bit deeper into the main reasons why you would use Spark. In short, for its distributed processing engine through Spark Clusters and it’s Query Optimization engine.
Spark Clustering
Let’s dive into what makes Spark so incredibly useful and the perfect fit to build data pipelines for data lakes and train ML models in the cloud. Spark Clustering.
The Spark Driver program
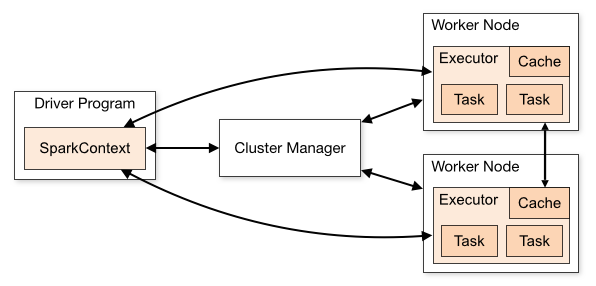
Spark applications run as independent sets of processes on a cluster. The SparkContext object coordinates these processes in your main program. We call this main program the driver program.
To run on a cluster the SparkContext object connects to a cluster manager like YARN or K8s. This cluster manager allocates resources across Spark applications. Once connected, the driver acquires executors on nodes in the cluster.
These executors form the processes that run computations and store data for your application. Next, the SparkContext object sends the application code (defined by JAR or Python files passed to SparkContext) to the executors. Finally, SparkContext sends tasks to the executors to run.
Most cloud platforms create the SparkContext and SparkSession objects automatically when running a program on a Spark cluster.
Spinning up a cluster
Through selection and configuration of the cluster in which you will run your spark program, you actually define how many workers and how many resources you will reserve for your Driver and Executors.
This is a bit different depending on the cloud platform. Some cloud platforms like Databricks will also automatically release the cluster when jobs are finished. This ensures you only pay for what you’re using. Isn’t that a charm.
When you use a cloud-platform, you don’t have to setup this whole configuration, nor do you need to know upfront how many Worker Nodes you’ll need. You can develop on small clusters and start to tweak and test performance and usage of resources while monitoring how Spark performs through its UI.
The Spark UI gives you
- A list of scheduler stages and tasks
- A summary of RDD sizes and memory usage
- Environmental information (variables, configuration etc.)
- Information about the running executors
- Information about Spark streaming jobs (since Spark 3.0.0)
Spark Query Optimization
All dataframe operations are going through a process called Query Optimization. The query optimizer will first optimize the plan before any execution will take place. Dataframes processing always happens in a lazy mode. The Plan is created first. Only when planning is completed, execution will start.

Analysis
Spark starts with analysing the relations/references to be derived. Either an abstract syntax tree (AST) returned by the SQL parser or a dataframe object created using the API define these relations/references. Both may contain unresolved attribute references or relations.
Unresolved means we don’t know the datatype or we haven’t matched the relation to an input table yet. Spark SQL makes use of Catalyst rules and a Catalog object that tracks data in all data sources to resolve these attributes.
The Optimizer first creates an unresolved logical plan, and then applies the following steps:
- Search the relation/reference by name from the Schema Catalog
- Map the name attribute, for example, col, to the input provided
- Determine which attributes match to the same value to give them a unique ID.
- Propagate and push datatypes through expressions
Optimization
In this phase the Optimizer applies the standard optimization rules to the logical plan. It includes constant folding, predicate pushdown, projection pruning and other rules.
Physical planning
In this phase, the optimizer creates one or more physical plans from the logical plan, using physical operators that match the Spark execution engine.
The physical planner applies the following:
- Select the physical plan using the cost model (e.g. to select join algorithms – for small relations a broadcast join will be used for instance)
- Pipeline projections or filters into one single map operation
- Push operations from the logical plan into data sources that support predicate or projection push-down
Code generation
The final phase of Spark SQL optimization is code generation. It involves generating Java bytecode to run on each machine.
Adaptive query planning
Since release 3.0.0 of Spark the Query Engine can also perform adaptive planning. Based on statistics of the finished plan nodes, Spark automatically re-optimizes the execution plan of the remaining queries.
Key take-away:
Spark’s distributed engine allows for fast processing on a cluster of machines, as well for data operations as ML operations. Spark Dataframe operations are optimized for performance through an Adaptive Query Engine Optimization process
This blog is part of our Data Lake Series: Data Lake – Reference Architecture
Want to know more?
Get in Touch
Originally I started my career as an expert in OO design and development.
I shifted more than 15 years ago to data warehousing and business intelligence and specialised in big data and data science.
My main interests are in deep learning and big data technologies.
My mission: store, process and deliver data fast, provide insights in data, design ML models and apply them to smart devices.
In my spare time I’m very passionate about Salsa dancing. So much that I performed internationally and that I have my own dance school where I teach LA style salsa.