Apache Spark GPU support

By now you should already have a fair understanding of the Apache Spark overall architecture. In this talk we’ll dive deeper into the GPU support features that Spark 3.0.0 added in June 2020. GPU stands for Graphical Processing Unit and there’s a very good reason why it’s supported in Apache Spark. Gone are the days when GPUs were only used for video processing, CAD and 3D tasks.
Today we use GPUs also for fast parallel processing of data streams in memory and hence GPUs lend themselves very well to support machine learning model inferencing and training. They now serve as AI accelerators, especially in the area of Deep Learning.
Think about for instance Deep Learning frameworks like PyTorch that natively provide support for training neural networks on GPU processors and inferencing those models on real-time data. The Apache Spark distributed computing system also fully supports GPU processing since its latest major version 3.
Accelerator-Aware Scheduling
Since release 3.0.0 GPUs are schedulable resources. We have the ability to
- request GPUs on Driver, Executor and/or Task level
- create simple scripts that automatically discover the GPUs on the nodes and use these scripts in the Spark configuration
- determine which resources have been assigned to which Driver, Executor or Task
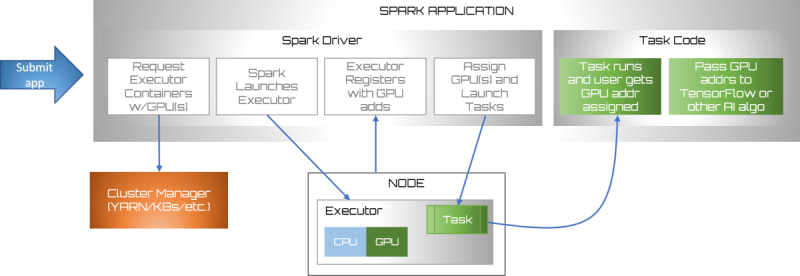
The GPU scheduling occurs as following:
- The Spark Driver requests Executor Containers with GPU(s)
- The cluster manager launches the Executor nodes
- Each Executor node registers itself with its GPU address(es)
- The driver assigns each Task to an executor and GPU and launches each task accordingly
- When each task runs it requests the GPU address assigned
- the task passes the GPU address to TensorFlow or another AI algorithm
SQL Columnar Processing
In addition the Spark development team extended the Catalyst API for columnar processing which enables efficient processing by vectorized accelerators for a.o. GPU processing.
This enables developers to also use the GPU for data processing pipelines and not merely for machine learning pipelines.

Before Spark 3.0.0 we had to separate data preparation from the machine learning pipeline (if we wanted to take advantage of GPUs supported by frameworks like XGBoost, TensorFlow and PyTorch). Now we can build data preparation and machine learning pipelines on the same clusters without the need for shared intermediate storage. By consequence also our ETL becomes GPU-accelerated and we can leverage the full power of GPUs for as well Spark ML as other powerful machine learning frameworks.
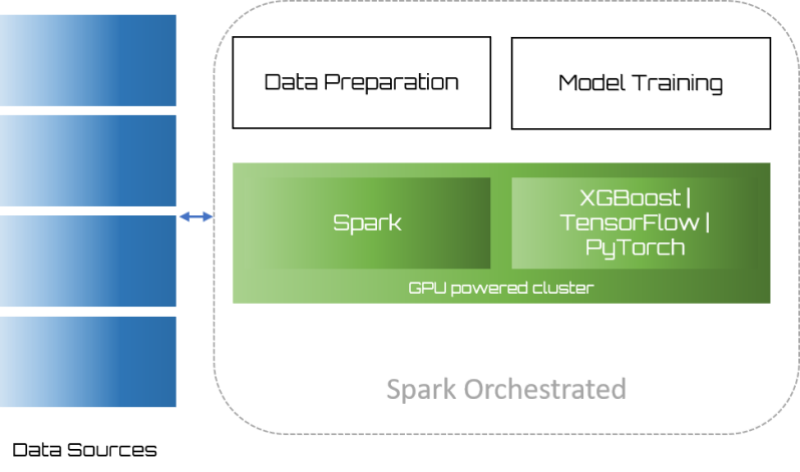
So we can create one single pipeline for
- data ingestion
- data preparation
- model training
Does this mean we should always use GPU for ETL purposes? Definitely not, it’s not a silver bullet nor the holy grail but when applied correctly it can provide tremendous performance gains.
This is definitely true for Apache Spark in the following cases:
- High cardinality data like join, aggregate and sort operations
- Large window operations
- Complicated processing
- Transcoding (e.g. encoding and compressing Parquet)
Spark Shuffle Operation optimizations
One of the main challenges in the Apache Spark architecture is designing and balancing shuffle operations well. With the GPU support NVIDIA also created a new Shuffle implementation. This shuffle implementation is built upon GPU-accelerated communication libraries, including UCX, RDMA, and NCCL. We’ll discuss this in another blog on tuning Apache Spark.
Key take-away:
Apache Spark comes with full GPU support for ML pipelines and data pipelines.
This leverages a powerful cloud-enabled platform for massive parallel data processing and ML processing
Check also these blog posts with respect to Apache Spark:
Want to know more?
Get in Touch
Originally I started my career as an expert in OO design and development.
I shifted more than 15 years ago to data warehousing and business intelligence and specialised in big data and data science.
My main interests are in deep learning and big data technologies.
My mission: store, process and deliver data fast, provide insights in data, design ML models and apply them to smart devices.
In my spare time I’m very passionate about Salsa dancing. So much that I performed internationally and that I have my own dance school where I teach LA style salsa.